2D人脸关键点的一些实验记录

2D人脸关键点
日常工作中需要使用到2D人脸关键点,近期查阅了一下资料发现对于目前对于这类任务的讨论与几年前(2018、2019)时的方案基本一致,主流且最常用的方案就是那几个:直接回归关键点坐标或offset坐标、使用类似人体关键点常用的那种热力图base的方案。简单来说前一个方案简单粗暴速度快,后一个方案效果好但是推理过程复杂且计算量大。
鉴于人脸面部信息的一些特殊性,比如人脸肌肉本身的表情的变化程度相对与其他一些关键点检测任务来说并不会特别大,比如人体、手部等肢体类的运动变化会大得许多。人脸面部表情通常难度就在夸张表情变化,如张嘴闭眼和挑眉等,然后就是头部姿态变化如pitch、yaw和roll进行一些大转角扭动。
通常在商用人脸关键点的检测任务中,对于头部姿态变化的要求并不会特别高,或者换句话说,大部分的业务场景都会牺牲一定的精度去换取一定的推理速度,所以我一般还是会选用直接回归坐标点的方式。通常这种方式对于人脸实时跟踪、稳定防抖和基础表情拟合等场景是最合适的,只能说这是一种均衡的方案,在保证一定精度的情况下,尽可能的提升推理速度。当然,如果是一些非实时的场景需要追求更高精度的关键点,如3D重建、皮肤分析等场景,可能采用热力图的方式会更好。
另外,之前看过一些别人家的模型方案直接推理回归出关键点坐标的同时还回归了每个关键点概率,如[x1, y1, p1, x2, y2, p2, …]。这种方案通常是先训练一个高精度准确的热力回归模型,然后在训练目标模型时或训练前对数据进行热力回归后采用softmax进行概率图谱的生成标定,再通过目标模型进行关键点与点概率的回归,通常这类任务是用于为关键点信息添加一层显式的质量属性,例如遮挡、模糊和光照不均等相关区域的关键点可以通过概率进行过滤,或者在推理时根据概率进行加权。
损失函数的选择
关于直接回归2D人脸关键点这项任务的损失函数的选用,我认为基本是属于经验主义,看过需求不同的paper和一些开源项目的方案,常见的基本是L1、L2、smooth L1、WingLoss、Adapt-WingLoss等等,还有其他很多方案。在我看来本质上就是设置一个监督2D点集的监督信号,哪个函数好哪个函数不好往往跟训练过程中的数据集分布、关键点数量、数据集质量、模型复杂度、训练策略、推理速度要求等都有关系。这里面最常见也是网络上最多人广泛使用的wingloss,关于wingloss的所谓原理不做过多的赘述,大概实现方案如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class WingLoss(nn.Module):
def __init__(self, w=10.0, d=2.0):
super(WingLoss, self).__init__()
self.w = w
self.d = d
self.C = w - w * np.log(1 + w/d)
def forward(self, pred, target):
x = torch.abs(target - pred)
x = torch.where(x < self.w,
self.w * torch.log(1 + x/self.d),
torch.abs(x) - self.C)
return torch.mean(x)
我们把各个常见的loss使用一组数据进行可视化,对比wingloss的方案,结果如下:
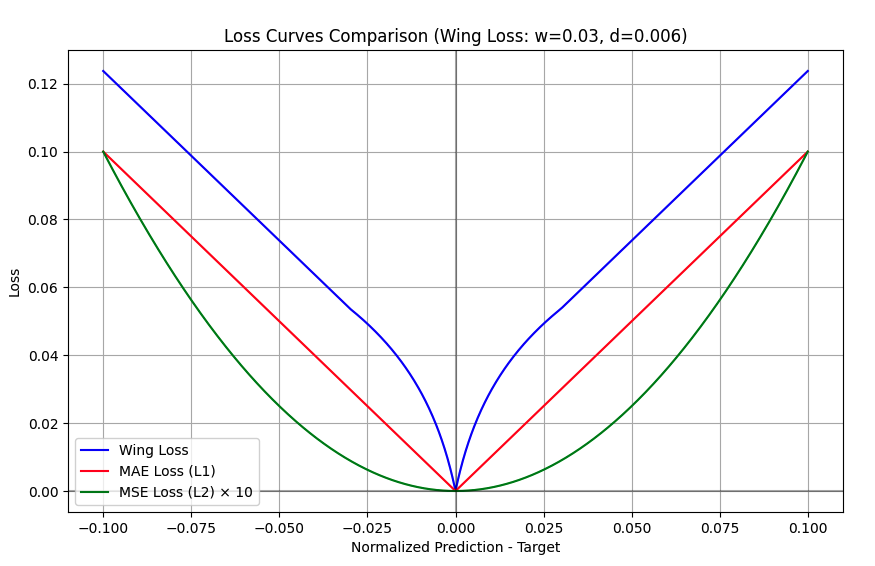
这个wingloss的曲线从视觉上来看是一种有目的的定制化复合函数,看似是为了解决在训练的不同阶段中遇到的某些问题,但是实际上我在经过多次的实验中,无论是回归点的精度还是稳定程度,wingloss在与MAE进行对比始终没有显著的效果提升,而且有多次出现MAE精度效果比wingloss更好,这可能与数据集的分布、关键点数量、数据集质量、模型复杂度、训练策略、推理速度要求等都有关系。
数据增强
对于人脸关键点的数据增强方案,基本与大部分的视觉任务大差不差,无非就是基于关键点任务有一些需要注意的地方,比如:
- 图像变换与关键点变换的映射关系,确保变换后的关键点信息与变换后的图像信息一致
- 实时跟踪任务最好加入微小的坐标扰动可带来大幅度的效果
- 训练最初阶段图像旋转增强的角度范围不宜过大(-20 ~ 20以内即可),当然需要根据需求和数据情况来定
- 如果需要做Flip增强,要注意左右点序和语义信息的变换,转换关键点flip索引序号是必要的(神坑)
- 数据的Crop留边需要适当的值,经验上来看通常均值定在(0.8x ~ 1.5x)范围内,要注意一些几何变换带来的便宜容易导效果变差
一个通用的数据增强方案,可以参考如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
class KeypointAugmentor:
def __init__(
self,
image_size: Tuple[int, int] = (112, 112),
is_val: bool = False,
rotation_range: int = 20,
scale_range: Tuple[float, float] = (0.0, 0.2),
brightness_range: Tuple[float, float] = (0.6, 1.3),
contrast_range: Tuple[float, float] = (0.6, 1.6),
noise_range: Tuple[int, int] = (16, 128),
blur_range: Tuple[int, int] = (3, 21),
flip_prob: float = 0.0,
general_prob: float = 0.5,
mode = "general",
):
self.flip_prob = flip_prob
self.mode = mode
self.is_val = is_val
if is_val:
self.transform = A.Compose([
A.LongestMaxSize(max_size=max(image_size)),
A.PadIfNeeded(
min_height=image_size[0],
min_width=image_size[1],
border_mode=cv2.BORDER_CONSTANT,
value=0
),
], keypoint_params=A.KeypointParams(format='xy', remove_invisible=False))
else:
self.transform = A.Compose([
A.RandomResizedCrop(
height=image_size[0],
width=image_size[1],
scale=(0.8, 1.0),
ratio=(0.7, 1.5),
p=general_prob
),
A.LongestMaxSize(max_size=max(image_size)),
A.PadIfNeeded(
min_height=image_size[0],
min_width=image_size[1],
border_mode=cv2.BORDER_CONSTANT,
value=0
),
A.ShiftScaleRotate(
shift_limit=0.1,
scale_limit=(scale_range[0], scale_range[1]),
rotate_limit=rotation_range,
border_mode=cv2.BORDER_CONSTANT,
p=general_prob,
),
A.OneOf([
A.GaussNoise(
var_limit=noise_range,
mean=0,
p=0.5
),
A.GaussianBlur(
blur_limit=blur_range,
p=0.5
),
A.ToGray(p=1.0),
], p=general_prob),
A.RandomBrightnessContrast(
brightness_limit=(brightness_range[0]-1, brightness_range[1]-1),
contrast_limit=(contrast_range[0]-1, contrast_range[1]-1),
p=general_prob
),
A.OneOf([
A.HueSaturationValue(
hue_shift_limit=50,
sat_shift_limit=50,
val_shift_limit=50,
p=0.5
),
A.RGBShift(
r_shift_limit=50,
g_shift_limit=50,
b_shift_limit=50,
p=0.5
),
], p=general_prob),
], keypoint_params=A.KeypointParams(format='xy', remove_invisible=False),
additional_targets={'class_labels': 'keypoints_labels'})
def __call__(
self,
image: np.ndarray,
keypoints: List[Tuple[float, float]],
) -> Dict:
if self.is_val:
cropped, lmk = square_crop_landmarks(keypoints, image, 1.2)
else:
scale = np.random.uniform(1.0, 1.5)
cropped, lmk = square_crop_landmarks(keypoints, image, scale, jitter_range=(0.00, 0.15))
transformed = self.transform(
image=cropped,
keypoints=lmk
)
return {
'image': transformed['image'],
'keypoints': transformed['keypoints'],
}
我的需求有检测一些非自然光的一些人脸关键点,如UV灯、蓝光、荧光灯等,所以会对数据进行一些特殊的光照处理:

特殊的训练技巧
通常我们的关键点数据都属于私有标注,可能关键点会与一些网络上的公开数据集存在一定的差异,我们希望自建的数据能借助网络大量的公开数据资源来完成训练,这类方法在计算机视觉与深度学习领域非常场景,如使用pretrain迁移学习或使用微调的方案等等。这边我们使用一个比较另类的方式进行实验:建立一个多头模型,同时回归多种标注数据类型的关键点,并在训练的过程中设置取不同种类关键点的数据进行按种类监督:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
class LandmarkTwoHeadsResNet(nn.Module):
def __init__(self, backbone='r18', num_landmarks_1=68, num_landmarks_2=106, num_landmarks_3=106):
super(LandmarkTwoHeadsResNet, self).__init__()
if backbone == 'r18':
self.backbone = resnet18(pretrained=False)
last_channel = 512
elif backbone == 'r34':
self.backbone = resnet34(pretrained=False)
last_channel = 512
elif backbone == 'r50':
self.backbone = resnet50(pretrained=False)
last_channel = 2048
else:
raise ValueError('backbone must be one of: r18, r34, r50')
self.features = nn.Sequential(*list(self.backbone.children())[:-2])
self.head1 = nn.Sequential(
nn.Conv2d(last_channel, 64, kernel_size=1), # 1x1 conv
nn.PReLU(),
nn.Flatten(),
nn.Linear(64 * 4 * 4, num_landmarks_1 * 2)
)
self.head2 = nn.Sequential(
nn.Conv2d(last_channel, 64, kernel_size=1), # 1x1 conv
nn.PReLU(),
nn.Flatten(),
nn.Linear(64 * 4 * 4, num_landmarks_2 * 2)
)
self.head3 = nn.Sequential(
nn.Conv2d(last_channel, 64, kernel_size=1), # 1x1 conv
nn.PReLU(),
nn.Flatten(),
nn.Linear(64 * 4 * 4, num_landmarks_3 * 2)
)
def forward(self, x):
features = self.features(x)
landmarks1 = self.head1(features)
landmarks2 = self.head2(features)
landmarks3 = self.head3(features)
return landmarks1, landmarks2, landmarks3
这种方案的优势在于:
- 所有关键点共享backbone,可以利用backbone的特征提取能力
- 减少实验的复杂度,方便调试多个数据集的训练情况
- 可以利用多个数据集的监督信号,选择不同数据集的部分关键点作为组合,形成一个更优的模型
因为我个人的标注数据总量并不多,尤其是在眼部、嘴部和眉毛等位置的数据太少,所以我依靠网络公开数据集的点与自主标注的轮廓点进行一定的组合,在经过600个epoch迭代后,最终效果如下:

最终关键点的MAE误差在左右,对于112x112的输入像素而言,平均误差大概在0.76个像素点。过多讨论数据集的val结果意义不大,因为标注质量和所遇的实际场景的差异性,通常现实中会遇到更多奇葩的问题。说白了这是一项目前数据质量的投入成本高于算法和模型本身的任务,起码对于目前研究现状来说,并没有看见非常显著有效的方案。
移动端跟踪
移动端的模型需要将模型进行蒸馏,整体架构与ResNet为backbone的模型没太大区别,把卷积层替换成Depthwise卷积或者直接使用MobileNets或ShuffleNets等轻量级的模型替换backbone,然后使用蒸馏的方式进行训练即可,基本上实时跟踪的速度在移动端上CPU上可以5ms一次的推理耗时。
