端到端的文档定位与校准算法
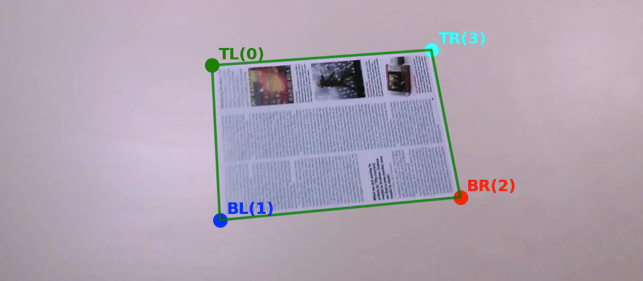
最近需要做一个类似扫描王那样的文档检测,搜索一下大多数网络上的资料都是类似使用传统算法去提取边缘信息再进行一些后处理得到文档轮廓。当然也有一些DNN的方案,比如hed边缘检测、语义分割纸张等。在当前年份也有人做一些比较深入的研究方向,比如弯曲的纸面使用非刚性变换去校准还原文档内容的方式。
当前我的需求比较简单,不需要考虑纸质弯曲变换,只考虑纸或证件放置于平面桌面的情况下即可。
最简单直观的方式就是找出文档的四个角点,然后使用透视变换进行对齐。
直接回归文档四个角的坐标点已经被证实了效果非常不好,原因大概是因为空间信息丢失,而且学习难度大,这边采用热力回归的方式,具体参考DSNT.
DSNT原理简述
- 传统的 argmax 从热图提取坐标是不可微的:
梯度无法反向传播,网络无法端到端训练。
- DSNT的解决方案是:
将热图转换为概率分布,然后计算期望值作为坐标。
步骤1:热图转概率(Spatial Softmax)
\[P(x,y) = \frac{e^{H(x,y)}}{\sum_{i,j} e^{H(i,j)}}\]其中 $H$ 是网络输出的热图,$P$ 是归一化后的概率分布。
步骤2:计算期望坐标
\(\hat{x} = \sum_{x,y} P(x,y) \cdot x\) \(\hat{y} = \sum_{x,y} P(x,y) \cdot y\)
这里的 $x, y$ 是预定义的坐标值(如归一化到 [-1, 1])。
- 为什么DSNT可微:
期望值计算是加权求和,完全可微:
\[\frac{\partial \hat{x}}{\partial H} = \frac{\partial}{\partial H}\left[\sum P(x,y) \cdot x\right]\]通过 softmax 的导数和链式法则,梯度可以传播回去:
\[\frac{\partial L}{\partial H} = P \cdot \left[(x - \hat{x})\frac{\partial L}{\partial \hat{x}} + (y - \hat{y})\frac{\partial L}{\partial \hat{y}}\right]\]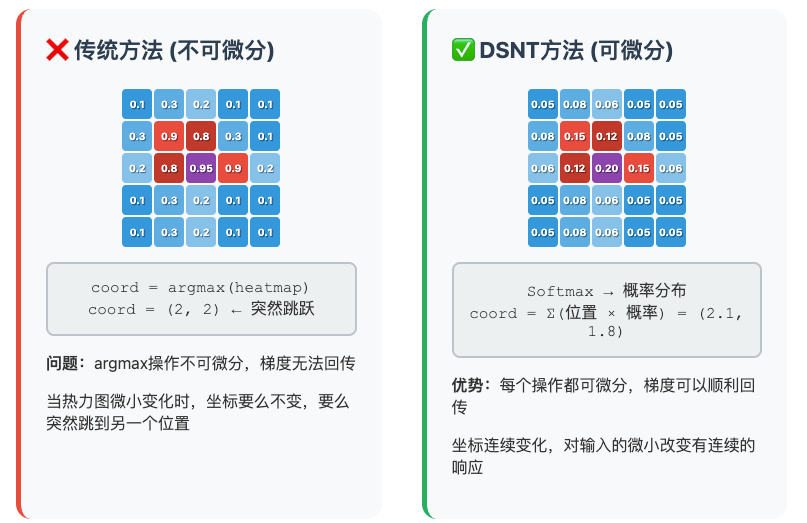
Pipeline流程
流程结构比较简单,与相对传统的方案去对比:
- 传统后处理方案:
1
2
3
4
5
6
7
8
9
10
# 训练流程
image → Backbone → 热图 → argmax(不可微) → 坐标
↑ ↓
监督信号 坐标损失
(热图损失) (无法传回去)
# 问题:
# - 必须用热图标签来监督
# - backbone学到的是"如何生成好看的热图"
# - 而不是"如何生成能准确定位的热图"
- DSNT后处理方案:
1
2
3
4
5
6
7
8
9
10
# 训练流程
image → Backbone → 热图 → DSNT(可微) → 坐标
↑ ↓
←←←←←←←←←←←←←←← 坐标损失
(梯度可以传回来)
# 优势:
# - 直接用坐标标签监督
# - backbone学到的是"如何生成能准确转换成坐标的热图"
# - 整个系统针对最终目标(坐标精度)优化
网络结构
考虑移动端实时需求,网络直接使用mobilenet,参考fpn的结构,把不同尺度的特征图谱用来连接上采样层进行一定的特征融合:
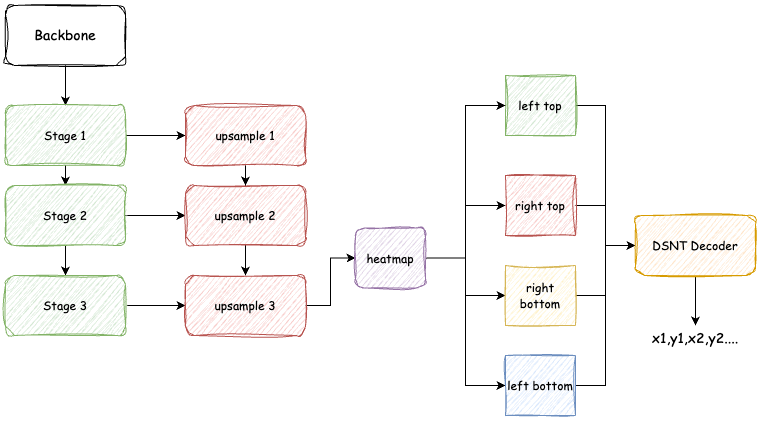
代码实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
class DocLocationNet(nn.Module):
def __init__(self, pretrained=False, input_size=(512, 512), num_corners=4,
use_stage=3, width_mult=1.0, activation="ReLU"):
super(DocLocationNet, self).__init__()
self.input_size = input_size
self.num_corners = num_corners
self.use_stage = use_stage
self.backbone = MobileNetV2(
width_mult=width_mult,
out_stages=(use_stage,),
activation=activation
)
# Determine the feature dimensions based on different stages
stage_channels = {
2: int(32 * width_mult), # 64x64
3: int(64 * width_mult), # 32x32
4: int(96 * width_mult), # 32x32
5: int(160 * width_mult), # 16x16
}
if use_stage not in stage_channels:
raise ValueError(f"Not supported stage: {use_stage}, supported stages: {list(stage_channels.keys())}")
backbone_out_channels = stage_channels[use_stage]
# Calculate the feature map size
stage_strides = {2: 8, 3: 16, 4: 16, 5: 32}
stride = stage_strides[use_stage]
self.feature_map_size = (input_size[0] // stride, input_size[1] // stride)
# Light-weight decoder - different strategies based on stage
if use_stage in [2]: # 64x64, only slight adjustment
self.decoder = nn.Sequential(
nn.Conv2d(backbone_out_channels, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, num_corners, kernel_size=3, padding=1),
)
self.target_size = self.feature_map_size # Use 64x64 directly
elif use_stage in [3, 4]: # 32x32, upsample to 64x64
self.decoder = nn.Sequential(
# First, compress the number of channels
nn.Conv2d(backbone_out_channels, 128, kernel_size=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
# Upsample 32x32 -> 64x64
nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, output_padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
# Generate heat map
nn.Conv2d(64, num_corners, kernel_size=3, padding=1),
)
self.target_size = (self.feature_map_size[0] * 2, self.feature_map_size[1] * 2)
else: # stage 5: 16x16, upsample to 64x64
self.decoder = nn.Sequential(
# First, compress the number of channels
nn.Conv2d(backbone_out_channels, 256, kernel_size=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
# First upsampling 16x16 -> 32x32
nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, output_padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
# Second upsampling 32x32 -> 64x64
nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, output_padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
# Generate heat map
nn.Conv2d(64, num_corners, kernel_size=3, padding=1),
)
self.target_size = (64, 64)
# Adaptive pooling to ensure consistent output size
self.adaptive_pool = nn.AdaptiveAvgPool2d(self.target_size)
# Initialize weights
self._initialize_weights()
def _initialize_weights(self):
"""Initialize the weights of the decoder"""
for m in self.decoder.modules():
if isinstance(m, (nn.ConvTranspose2d, nn.Conv2d)):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self, x):
"""
Forward propagation - only return heat maps
"""
# Feature extraction - use the specified stage
features_tuple = self.backbone(x)
features = features_tuple[0]
# Decode to generate heat maps
heatmaps = self.decoder(features)
# Ensure the heat map size is consistent
heatmaps = self.adaptive_pool(heatmaps)
# Only return heat maps, post-processing is done externally
return heatmaps
DSNT的decoder代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
class HeatmapToCoords(nn.Module):
"""
Differentiable Spatial to Numerical Transform Module
"""
def __init__(self, normalized_coordinates=True):
super(HeatmapToCoords, self).__init__()
self.normalized_coordinates = normalized_coordinates
def forward(self, heatmaps):
"""
Use marginalization strategy to avoid creating large arrays
"""
spatial_dims = heatmaps.size()[2:]
# Generate coordinate vectors (not grids)
if self.normalized_coordinates:
coords_1d = []
for dim_size in spatial_dims:
first_coord = -(dim_size - 1.0) / dim_size
coords = torch.arange(dim_size, dtype=heatmaps.dtype, device=heatmaps.device)
coords = coords * (2.0 / dim_size) + first_coord
coords_1d.append(coords)
else:
coords_1d = [torch.arange(d, dtype=heatmaps.dtype, device=heatmaps.device)
for d in spatial_dims]
# Use marginalization to calculate expectations
expectations = []
for dim_idx in range(len(spatial_dims)):
# Marginalize: Sum over all dimensions except the current one
marg_probs = heatmaps
for other_dim in reversed(range(len(spatial_dims))):
if other_dim != dim_idx:
marg_probs = marg_probs.sum(dim=other_dim + 2, keepdim=False)
# Calculate expectations for the current dimension
expectation = (marg_probs * coords_1d[dim_idx]).sum(dim=-1, keepdim=False)
expectations.append(expectation)
# Stack and flip coordinates
result = torch.stack(expectations, dim=-1)
return result[..., [1, 0]] if result.size(-1) == 2 else result.flip(-1)
def extra_repr(self):
return f'normalized_coordinates={self.normalized_coordinates}'
class HeatmapNormalize(nn.Module):
"""
Spatial Softmax Module
Normalize spatial dimensions of a multi-dimensional spatial tensor
"""
def __init__(self):
super(HeatmapNormalize, self).__init__()
def forward(self, inp):
"""
Use different versions of flat_softmax implementation
Use flatten/unflatten instead of view + reduce
"""
# Save original shape
original_shape = inp.shape
# Use flatten to flatten spatial dimensions (from second dimension)
flattened = inp.flatten(start_dim=2) # (batch, channels, spatial_flattened)
# Apply softmax to spatial dimensions
softmax_result = F.softmax(flattened, dim=-1)
# Use unflatten to restore spatial dimension shape
result = softmax_result.unflatten(dim=2, sizes=original_shape[2:])
return result
def extra_repr(self):
return 'spatial_dims=2+, preserve_batch_channel=True'
class HeatmapDecoder(nn.Module):
"""
Heat Map Decoder: Convert Original Heat Map to Coordinates
Combines the functionality of HeatmapNormalize and HeatmapToCoords
"""
def __init__(self, normalized_coordinates=True):
super(HeatmapDecoder, self).__init__()
self.normalized_coordinates = normalized_coordinates
# Use existing two modules
self.heatmap_normalize = HeatmapNormalize()
self.heatmap_to_coords = HeatmapToCoords(normalized_coordinates)
def forward(self, heatmaps):
"""
Full Heat Map Decoding Process
Args:
heatmaps: Original Heat Map (B, C, H, W)
Returns:
dict: {
'coords': Decoded Coordinates,
'heatmaps_normalized': Normalized Heat Map (For Loss Calculation)
}
"""
# 1. Normalized Heat Map (softmax)
heatmaps_normalized = self.heatmap_normalize(heatmaps)
# 2. Extract Coordinates
coords = self.heatmap_to_coords(heatmaps_normalized)
return {
'coords': coords,
'heatmaps_normalized': heatmaps_normalized
}
def extra_repr(self):
return f'normalized_coordinates={self.normalized_coordinates}'
def heatmap_to_coords(heatmaps, normalized_coordinates=True):
module = HeatmapToCoords(normalized_coordinates)
return module(heatmaps)
def heatmap_normalize(inp):
module = HeatmapNormalize()
return module(inp)
def heatmap_decode(heatmaps, normalized_coordinates=True):
module = HeatmapDecoder(normalized_coordinates)
return module(heatmaps)
通过model推理后,获取到的文档四个角点的预期热力图可视化如下:
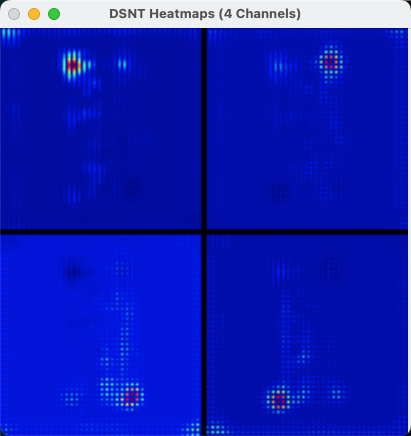
可以明显的看到四个角点在分别对应的四个通道上都有热力信息,通过DSNT解码后即可获取到具体的坐标点:

训练结果
这边准备了一批纸质文档拍照的数据集进行训练,大概经过了10万次的迭代后,得到了还不错的效果:

训练过程中开启了一些较为复杂数据增强,导致train loss会比val loss高非常多。
不过这种方案其实缺陷还是挺大的,对业务场景要求较高,比如只能允许目标在画面中,如果四个角点其中一个在画面外效果就会变差,还有四个角点的顺序纯在一定的语义信息绑定,在做一些旋转方案的信息需要注意预测失败的情况。