跨平台的人脸SDK工程设计

对算法SDK思考
在工程质量、多平台支持、项目易用性以及性能上的优化如果保持较高的要求,实际上哪怕是现在(2025年)被人经常调侃的”人脸已经烂大街”的人脸项目,开发起来也不是一个小的工作量。
人脸作为一路陪伴AI成长起来的一个长久话题,从较早的机器学习到现在的深度学习,一直是一个非常火热的Topic,可延伸出来的一些分支任务如人脸特征提取、关键点定位、表情分析、属性分析、换脸等等,品类也是非常丰富。
实现一个跨平台的通用算法落地SDK框架,最底层的逻辑就是如何通用,在不一样的CPU架构、平台设备、系统以及不同版本的开发环境下如何实现最大程度的兼容,这个是最基本也是最核心需要思考的问题,例如当前移动互联时代下市场上最常见的Windows PC、Linux、Android、iOS、HarmonyOS以及一些基于arm的嵌入式设备等等。
除此之外,在完善基础功能架构的后,也需要考虑一些应对不同的平台、设备的差异进行专门优化,如OpenCL、OpenGL、Arm Neon、Intel SSE、CUDA、NPU等等可以在特殊设备上提升计算速度的方案。
在考虑到底层设备功能相关的支持后,我们需要去寻找一些案例。从Github上能看到的都是一些集成demo的项目居多,该类型的项目对开发者熟悉和迁移一个算法的Inference是非常友好的,但是如果想利用该项目进行项目化的集成,那需要思考的地方还是挺多的。
所以在开发一个可商用落地的SDK项目个人认为还是有必要的。
项目整体配置方案
基本语言
在项目主工程使用C/C++进行开发这点是没有太大争议的,毕竟简单粗暴的讲,既然需要跨平台跨语言,那么基本上C/C++可支持的范围在高级编程语言里应该是最广的。虽然很多人都会选择使用Python进行项目部署落地,但是这种方案对移动端设备支持会较差,比如Android和iOS。
构建工具使用CMake,在跨平台下有非常好的兼容性,并且可翻阅的文档较多,当然也有在CMake和XMake中纠结过,毕竟XMake是一个非常优秀的项目,但是考虑到目前更多开发者对其不熟悉,后续可能考虑同时适配。
得益于C/C++兼容性优势的情况下,后我们想使用Java、Python、Kotlin、JavaScript、Objective-C、Golang等各种主流的编程语言进行Native方式的调用都是非常方便的。
推理框架模块
一个深度学习为基底的项目,选择一个推理框架是必须要做的事,我们将推理部分进行抽象设计后,认为模型 推理的引擎主要分为CPU和Other,CPU推理应该是作为最基础的功能,他应该支持任何设备,而Other则作为对一些可支持推理提速的设备进行额外的特殊支持,整体的技术实现如下:
- CPU(任何设备/平台)
- Other
- CUDA
- CoreML
- XX-NPU
- ….
优秀的推理框架非常多,如ONNXRuntime、OpenVino、NCNN、MNN、TEngine等等,在inspireface当前的版本,我们选用MNN作为CPU的基础版本推理框架。我们在项目中设计了一个轻量的推理框架兼容器AnyNet,可以很容易的实现在顶层接口不变的情况下,对底层推理框架的抽象实现和适配,所以我们在开发项目的过程中可以很快速的集成新的推理框架,并且快速完成测试和验证。
图像处理模块
作为一个图像的项目,这个步骤可以说必不可少的,最初我们集成了OpenCV,但是在程序不断的更迭过程中和几次与客户对接时,我们发现OpenCV对于我们这个项目它有点太大了,并且在一些特殊的环境下可能会出现一些函数符号冲突的问题。考虑到InspireFace的项目性质,我们使用到的图像处理API其实并不算多,主要围绕在一些几何图形变换上,这些其实是可以通过自己手动实现的方式,来降低集成难度和发生错误的概率。
我们重新为InspireFace这类轻量化的算法SDK专门设计了一个更加轻量化的图像处理库:InspireCV。它包含了一些最常用的图像2D几何变换,也支持仿射变换、相似变换等一些教高级的API功能,同时我们还尝试了使用硬件加速的方案如Arm Neon在Arm设备上进行提速,利用如RK这类嵌入式设备提供的利用DMA和特殊图形处理芯片加速图像处理的API适配。总之InspireCV在InspireFace上集成是可工作的,并且为我们节约了非常多调试bug的时间。
模型管理模块
在项目需要使用到多个模型的时候,这是非常头疼的问题,毕竟需要考虑到一些小内存的嵌入式设备部署,如何最小化的利用到需要的模型从而节约更多的内存空间,这是需要思考的问题。
我们自己设计了一个简单的模型包管理工具,利用yaml文件作为存储各个模型的基础信息,使用归档的形式进行打包,这样的好处是在读取模型时,可以根据用户的配置进行选择需要读取的模型,避免全部加载进内存中,并且我们还设计了懒加载的读取方式,可以避免同一时刻加载过多模型导致的卡顿问题。
在存储模型信息的单元,我们配好AnyNet参数设计将配置文件进行了统一化的格式输入,这样无论是发布还是持续开发集成新的模型都可以带来较快的迭代速度。
架构设计
在架构的设计上,我们采用一个全局单例上下文控制器(App Context)和算法会话(Face Session)的一个主要模式进行拆解。
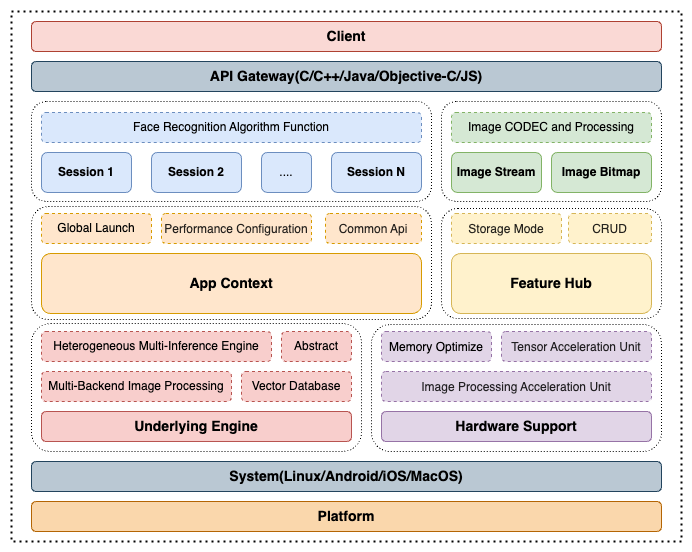
App Context
App Context主要负责一些全局性的功能,如加载模型文件、读取或修改一些全局配置等。他的目的是给使用者提供一个可全局调度和分配管理一些对象的功能。
Face Session
Face Session采用会话式的内存管理,所有与人脸相关业务的算法处理均集中在session对象中,session对象可以创建多个如应对多线程的任务场景;但是不同的session之间的缓存数据不应该被混用,尤其是在一些依赖多次输入输出的数据,如人脸跟踪任务的缓存,一旦混用会造成错误。session和session之间始终保持数据独立且隔离的状态。